Efficiently Modeling Long Sequences with Structured State Spaces
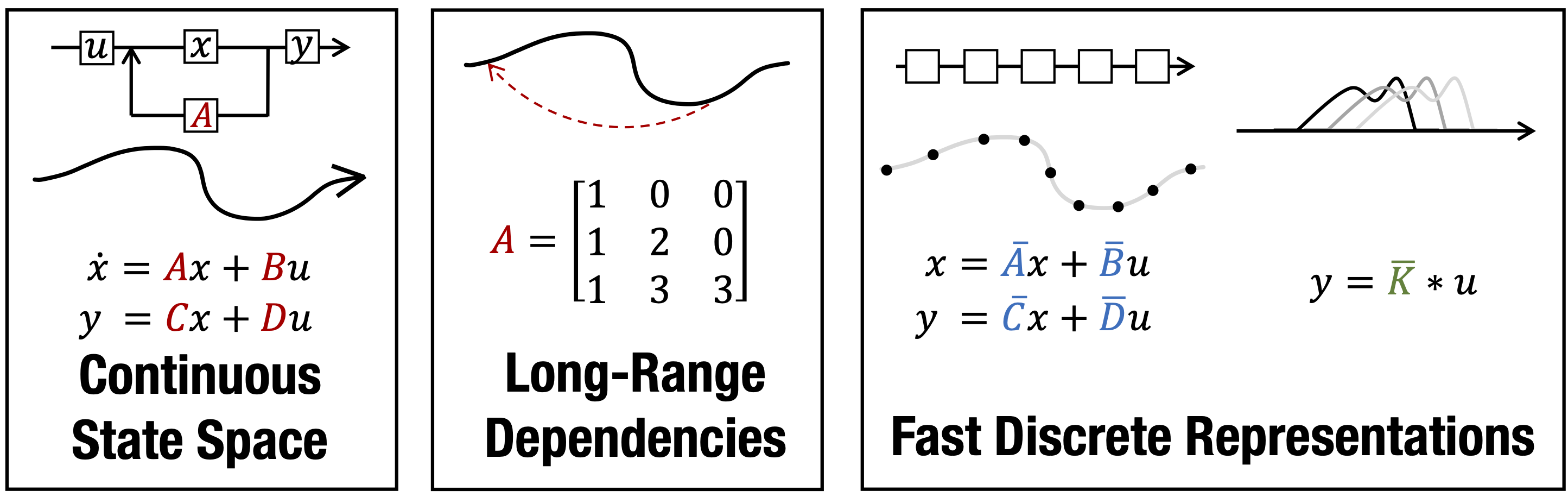
A central goal of sequence modeling is designing a single principled model that can address sequence data across a range of modalities and tasks, particularly on long-range dependencies. Although conventional models including RNNs, CNNs, and Transformers have specialized variants for capturing long dependencies, they still struggle to scale to very long sequences of $10000$ or more steps. A promising recent approach proposed modeling sequences by simulating the fundamental state space model (SSM) \( x'(t) = Ax(t) + Bu(t), y(t) = Cx(t) + Du(t) \), and showed that for appropriate choices of the state matrix \( A \), this system could handle long-range dependencies mathematically and empirically. However, this method has prohibitive computation and memory requirements, rendering it infeasible as a general sequence modeling solution. We propose the Structured State Space sequence model (S4) based on a new parameterization for the SSM, and show that it can be computed much more efficiently than prior approaches while preserving their theoretical strengths. Our technique involves conditioning \( A \) with a low-rank correction, allowing it to be diagonalized stably and reducing the SSM to the well-studied computation of a Cauchy kernel. S4 achieves strong empirical results across a diverse range of established benchmarks, including (i) 91\% accuracy on sequential CIFAR-10 with no data augmentation or auxiliary losses, on par with a larger 2-D ResNet, (ii) substantially closing the gap to Transformers on image and language modeling tasks, while performing generation $60\times$ faster (iii) SoTA on every task from the Long Range Arena benchmark, including solving the challenging Path-X task of length 16k that all prior work fails on, while being as efficient as all competitors.
PDF Abstract ICLR 2022 PDF ICLR 2022 Abstract







 MNIST
MNIST
 WikiText-2
WikiText-2
 WikiText-103
WikiText-103
 Speech Commands
Speech Commands

