Improving language models by retrieving from trillions of tokens
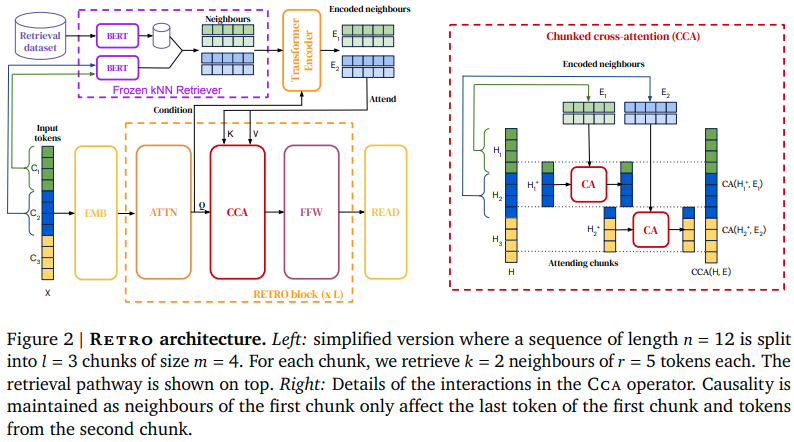
We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a $2$ trillion token database, our Retrieval-Enhanced Transformer (RETRO) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25$\times$ fewer parameters. After fine-tuning, RETRO performance translates to downstream knowledge-intensive tasks such as question answering. RETRO combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. We typically train RETRO from scratch, yet can also rapidly RETROfit pre-trained transformers with retrieval and still achieve good performance. Our work opens up new avenues for improving language models through explicit memory at unprecedented scale.
PDF AbstractCode




 Natural Questions
Natural Questions
 WikiText-2
WikiText-2
 C4
C4
 WikiText-103
WikiText-103
 The Pile
The Pile
 LAMBADA
LAMBADA
Results from the Paper
 Ranked #1 on
Language Modelling
on WikiText-103
(using extra training data)
Ranked #1 on
Language Modelling
on WikiText-103
(using extra training data)
