OmniNet: Omnidirectional Representations from Transformers
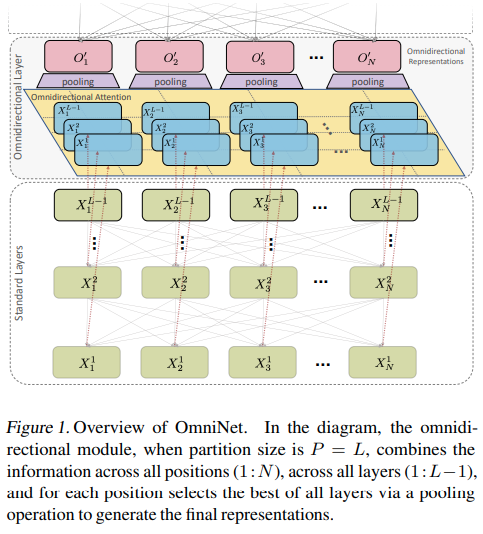
This paper proposes Omnidirectional Representations from Transformers (OmniNet). In OmniNet, instead of maintaining a strictly horizontal receptive field, each token is allowed to attend to all tokens in the entire network. This process can also be interpreted as a form of extreme or intensive attention mechanism that has the receptive field of the entire width and depth of the network. To this end, the omnidirectional attention is learned via a meta-learner, which is essentially another self-attention based model. In order to mitigate the computationally expensive costs of full receptive field attention, we leverage efficient self-attention models such as kernel-based (Choromanski et al.), low-rank attention (Wang et al.) and/or Big Bird (Zaheer et al.) as the meta-learner. Extensive experiments are conducted on autoregressive language modeling (LM1B, C4), Machine Translation, Long Range Arena (LRA), and Image Recognition. The experiments show that OmniNet achieves considerable improvements across these tasks, including achieving state-of-the-art performance on LM1B, WMT'14 En-De/En-Fr, and Long Range Arena. Moreover, using omnidirectional representation in Vision Transformers leads to significant improvements on image recognition tasks on both few-shot learning and fine-tuning setups.
PDF Abstract



 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 Oxford 102 Flower
Oxford 102 Flower
 C4
C4
 WMT 2014
WMT 2014
