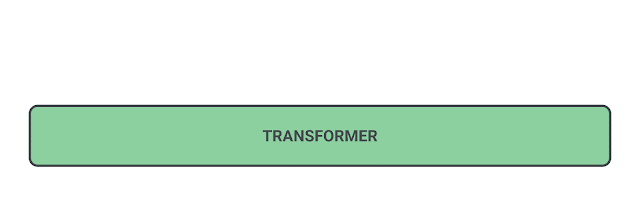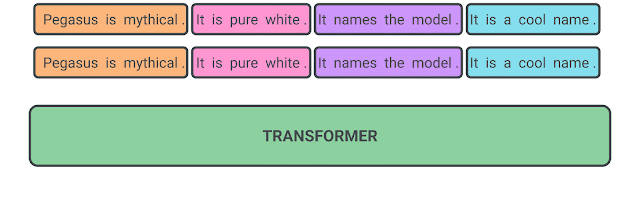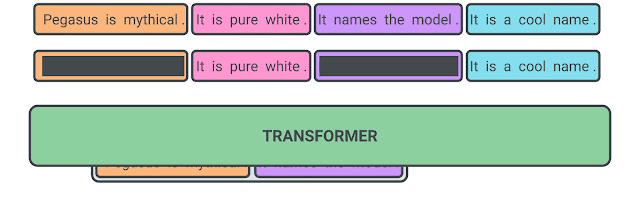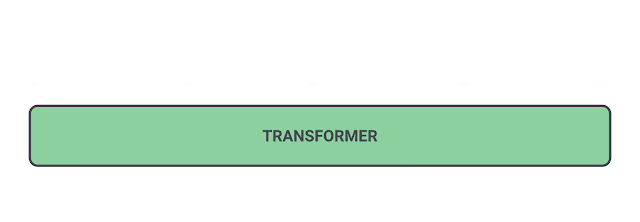
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
Recent work pre-training Transformers with self-supervised objectives on large text corpora has shown great success when fine-tuned on downstream NLP tasks including text summarization. However, pre-training objectives tailored for abstractive text summarization have not been explored. Furthermore there is a lack of systematic evaluation across diverse domains. In this work, we propose pre-training large Transformer-based encoder-decoder models on massive text corpora with a new self-supervised objective. In PEGASUS, important sentences are removed/masked from an input document and are generated together as one output sequence from the remaining sentences, similar to an extractive summary. We evaluated our best PEGASUS model on 12 downstream summarization tasks spanning news, science, stories, instructions, emails, patents, and legislative bills. Experiments demonstrate it achieves state-of-the-art performance on all 12 downstream datasets measured by ROUGE scores. Our model also shows surprising performance on low-resource summarization, surpassing previous state-of-the-art results on 6 datasets with only 1000 examples. Finally we validated our results using human evaluation and show that our model summaries achieve human performance on multiple datasets.
PDF Abstract ICML 2020 PDF

 Colab
Colab


 C4
C4
 CNN/Daily Mail
CNN/Daily Mail
 WebText
WebText
 WikiHow
WikiHow
 NEWSROOM
NEWSROOM
 Reddit TIFU
Reddit TIFU
 BillSum
BillSum
 XSum
XSum

