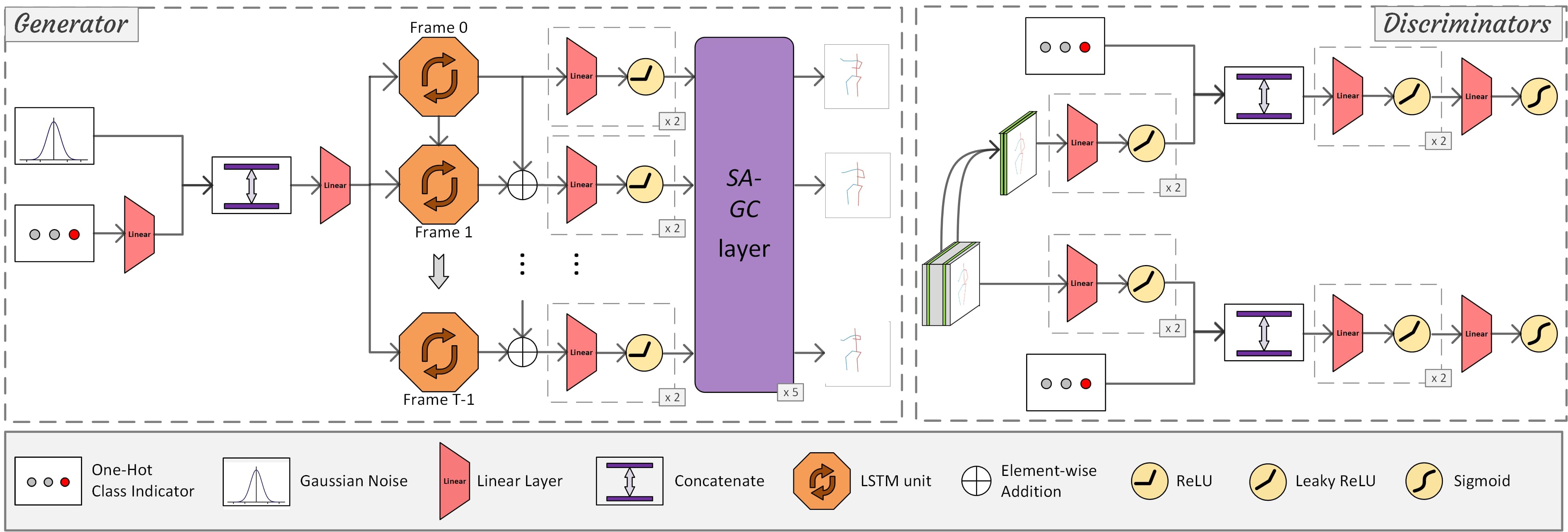
Structure-Aware Human-Action Generation
Generating long-range skeleton-based human actions has been a challenging problem since small deviations of one frame can cause a malformed action sequence. Most existing methods borrow ideas from video generation, which naively treat skeleton nodes/joints as pixels of images without considering the rich inter-frame and intra-frame structure information, leading to potential distorted actions. Graph convolutional networks (GCNs) is a promising way to leverage structure information to learn structure representations. However, directly adopting GCNs to tackle such continuous action sequences both in spatial and temporal spaces is challenging as the action graph could be huge. To overcome this issue, we propose a variant of GCNs to leverage the powerful self-attention mechanism to adaptively sparsify a complete action graph in the temporal space. Our method could dynamically attend to important past frames and construct a sparse graph to apply in the GCN framework, well-capturing the structure information in action sequences. Extensive experimental results demonstrate the superiority of our method on two standard human action datasets compared with existing methods.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract



 Human3.6M
Human3.6M
 NTU RGB+D
NTU RGB+D
 NTU RGB+D 2D
NTU RGB+D 2D

