Subword Semantic Hashing for Intent Classification on Small Datasets
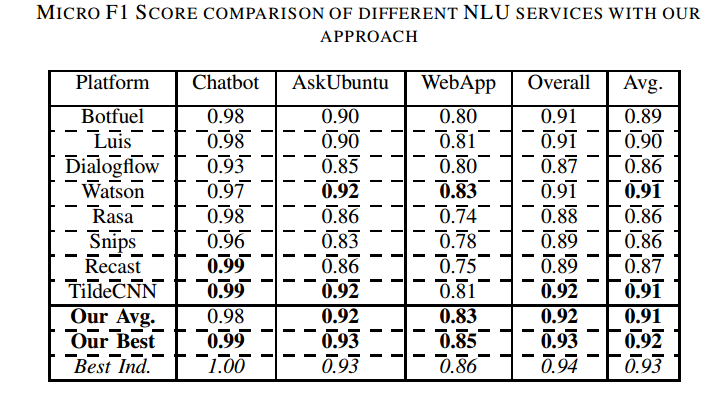
In this paper, we introduce the use of Semantic Hashing as embedding for the task of Intent Classification and achieve state-of-the-art performance on three frequently used benchmarks. Intent Classification on a small dataset is a challenging task for data-hungry state-of-the-art Deep Learning based systems. Semantic Hashing is an attempt to overcome such a challenge and learn robust text classification. Current word embedding based are dependent on vocabularies. One of the major drawbacks of such methods is out-of-vocabulary terms, especially when having small training datasets and using a wider vocabulary. This is the case in Intent Classification for chatbots, where typically small datasets are extracted from internet communication. Two problems arise by the use of internet communication. First, such datasets miss a lot of terms in the vocabulary to use word embeddings efficiently. Second, users frequently make spelling errors. Typically, the models for intent classification are not trained with spelling errors and it is difficult to think about ways in which users will make mistakes. Models depending on a word vocabulary will always face such issues. An ideal classifier should handle spelling errors inherently. With Semantic Hashing, we overcome these challenges and achieve state-of-the-art results on three datasets: AskUbuntu, Chatbot, and Web Application. Our benchmarks are available online: https://github.com/kumar-shridhar/Know-Your-Intent
PDF Abstract





 SNIPS
SNIPS
