Video Generation
241 papers with code • 15 benchmarks • 14 datasets
( Various Video Generation Tasks. Gif credit: MaGViT )

Benchmarks
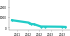
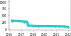
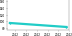
These leaderboards are used to track progress in Video Generation
| Trend | Dataset | Best Model | Paper | Code | Compare |
|---|---|---|---|---|---|
|
|||||
|
|||||

|
|||||

|
|||||

|
|||||

|
|||||
|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
Libraries
Use these libraries to find Video Generation models and implementationsDatasets
 UCF101
UCF101
 Kinetics
Kinetics
 MSR-VTT
MSR-VTT
 WebVid
WebVid
 LAION-400M
LAION-400M
 Kinetics-600
Kinetics-600
 How2Sign
How2Sign
 BAIR Robot Pushing
BAIR Robot Pushing

Most implemented papers
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
bioinf-jku/TTUR
•
 •
NeurIPS 2017
•
NeurIPS 2017
Generative Adversarial Networks (GANs) excel at creating realistic images with complex models for which maximum likelihood is infeasible.
Everybody Dance Now
carolineec/EverybodyDanceNow
•
 •
ICCV 2019
•
ICCV 2019
This paper presents a simple method for "do as I do" motion transfer: given a source video of a person dancing, we can transfer that performance to a novel (amateur) target after only a few minutes of the target subject performing standard moves.
Learning Temporal Coherence via Self-Supervision for GAN-based Video Generation
thunil/TecoGAN
•
•
Additionally, we propose a first set of metrics to quantitatively evaluate the accuracy as well as the perceptual quality of the temporal evolution.
Consistency Models
Through extensive experiments, we demonstrate that they outperform existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new state-of-the-art FID of 3. 55 on CIFAR-10 and 6. 20 on ImageNet 64x64 for one-step generation.
MoCoGAN: Decomposing Motion and Content for Video Generation
sergeytulyakov/mocogan
•
•
CVPR 2018
The proposed framework generates a video by mapping a sequence of random vectors to a sequence of video frames.
Temporal Generative Adversarial Nets with Singular Value Clipping
universome/stylegan-v
•
•
ICCV 2017
In this paper, we propose a generative model, Temporal Generative Adversarial Nets (TGAN), which can learn a semantic representation of unlabeled videos, and is capable of generating videos.
Stochastic Adversarial Video Prediction
alexlee-gk/video_prediction
•
•
ICLR 2019
However, learning to predict raw future observations, such as frames in a video, is exceedingly challenging -- the ambiguous nature of the problem can cause a naively designed model to average together possible futures into a single, blurry prediction.
Collaborative Neural Rendering using Anime Character Sheets
Drawing images of characters with desired poses is an essential but laborious task in anime production.
Unsupervised Learning for Physical Interaction through Video Prediction
tensorflow/models
•
•
NeurIPS 2016
A core challenge for an agent learning to interact with the world is to predict how its actions affect objects in its environment.
Stochastic Variational Video Prediction
RoboTurk-Platform/roboturk_real_dataset
•
•
ICLR 2018
We find that our proposed method produces substantially improved video predictions when compared to the same model without stochasticity, and to other stochastic video prediction methods.
