Abstractive Text Summarization
325 papers with code • 19 benchmarks • 48 datasets
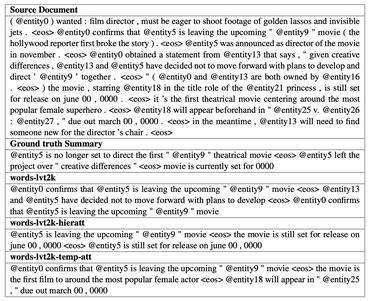
Abstractive Text Summarization is the task of generating a short and concise summary that captures the salient ideas of the source text. The generated summaries potentially contain new phrases and sentences that may not appear in the source text.
Source: Generative Adversarial Network for Abstractive Text Summarization
Image credit: Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond
Benchmarks
These leaderboards are used to track progress in Abstractive Text Summarization
| Trend | Dataset | Best Model | Paper | Code | Compare |
|---|---|---|---|---|---|
|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
Libraries
Use these libraries to find Abstractive Text Summarization models and implementationsDatasets
 Reddit
Reddit
 CNN/Daily Mail
CNN/Daily Mail
 New York Times Annotated Corpus
New York Times Annotated Corpus
 WikiHow
WikiHow
 SAMSum
SAMSum
 NEWSROOM
NEWSROOM
 LCSTS
LCSTS
 WikiSum
WikiSum
 WikiLingua
WikiLingua
 Reddit TIFU
Reddit TIFU
Subtasks
Most implemented papers
Attention Is All You Need
tensorflow/tensor2tensor
•
 •
NeurIPS 2017
•
NeurIPS 2017
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration.
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
huggingface/transformers
•
 •
ACL 2020
•
ACL 2020
We evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token.
Get To The Point: Summarization with Pointer-Generator Networks
abisee/pointer-generator
•
•
ACL 2017
Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization (meaning they are not restricted to simply selecting and rearranging passages from the original text).
Text Summarization with Pretrained Encoders
nlpyang/PreSumm
•
•
IJCNLP 2019
For abstractive summarization, we propose a new fine-tuning schedule which adopts different optimizers for the encoder and the decoder as a means of alleviating the mismatch between the two (the former is pretrained while the latter is not).
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
google-research/pegasus
•
•
ICML 2020
Recent work pre-training Transformers with self-supervised objectives on large text corpora has shown great success when fine-tuned on downstream NLP tasks including text summarization.
A Deep Reinforced Model for Abstractive Summarization
theamrzaki/text_summurization_abstractive_methods
•
•
ICLR 2018
We introduce a neural network model with a novel intra-attention that attends over the input and continuously generated output separately, and a new training method that combines standard supervised word prediction and reinforcement learning (RL).
Unified Language Model Pre-training for Natural Language Understanding and Generation
microsoft/unilm
•
•
NeurIPS 2019
This paper presents a new Unified pre-trained Language Model (UniLM) that can be fine-tuned for both natural language understanding and generation tasks.
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
On a wide range of tasks across NLU, conditional and unconditional generation, GLM outperforms BERT, T5, and GPT given the same model sizes and data, and achieves the best performance from a single pretrained model with 1. 25x parameters of BERT Large , demonstrating its generalizability to different downstream tasks.
R-Drop: Regularized Dropout for Neural Networks
dropreg/R-Drop
•
 •
NeurIPS 2021
•
NeurIPS 2021
Dropout is a powerful and widely used technique to regularize the training of deep neural networks.
Bottom-Up Abstractive Summarization
We use this selector as a bottom-up attention step to constrain the model to likely phrases.
