Language Modelling
4482 papers with code • 51 benchmarks • 157 datasets
Language Modeling is the task of predicting the next word or character in a document. This technique can be used to train language models that can further be applied to a wide range of natural language tasks like text generation, text classification, and question answering.
Historically, language modelling was done with N-gram language models (which still have niche uses), but since the 2010s neural language models took over, and starting from the 2020s SOTA was achieved exclusively with large language models (LLMs).
A model's language modeling capability is measured using cross-entropy and perplexity. Some datasets to evaluate language modeling are WikiText-103, One Billion Word, Text8, C4, The Pile, among others.
Some notable state-of-the-art language models include:
Check below for all state-of-the-art models.
Here are some additional readings to go deeper on the task:
- Language Modeling - Lena Voita
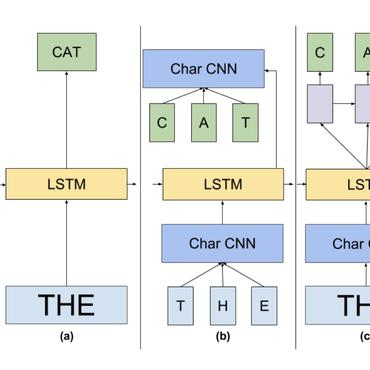
( Image credit: Exploring the Limits of Language Modeling )
Benchmarks
These leaderboards are used to track progress in Language Modelling
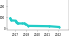
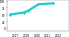
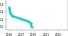
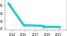
| Trend | Dataset | Best Model | Paper | Code | Compare |
|---|---|---|---|---|---|
|
|||||
|
|||||
|
|||||
|
|||||
|
|||||
|
|||||
|
|||||
|
|||||
|
|||||
|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
|||||

|
Libraries
Use these libraries to find Language Modelling models and implementationsDatasets
 IMDb Movie Reviews
IMDb Movie Reviews
 Pubmed
Pubmed
 Penn Treebank
Penn Treebank
 WikiText-2
WikiText-2
 C4
C4
 WikiText-103
WikiText-103
 BookCorpus
BookCorpus
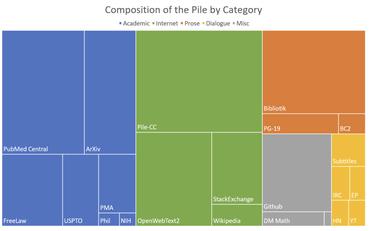 The Pile
The Pile
 BIG-bench
BIG-bench
Subtasks

Most implemented papers
Semi-supervised Sequence Learning
tensorflow/models
•
 •
NeurIPS 2015
•
NeurIPS 2015
In our experiments, we find that long short term memory recurrent networks after being pretrained with the two approaches are more stable and generalize better.
Universal Language Model Fine-tuning for Text Classification
Inductive transfer learning has greatly impacted computer vision, but existing approaches in NLP still require task-specific modifications and training from scratch.
RoBERTa: A Robustly Optimized BERT Pretraining Approach
pytorch/fairseq
•
 •
•
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging.
Generating Sequences With Recurrent Neural Networks
This paper shows how Long Short-term Memory recurrent neural networks can be used to generate complex sequences with long-range structure, simply by predicting one data point at a time.
DARTS: Differentiable Architecture Search
This paper addresses the scalability challenge of architecture search by formulating the task in a differentiable manner.
Language Models are Few-Shot Learners
By contrast, humans can generally perform a new language task from only a few examples or from simple instructions - something which current NLP systems still largely struggle to do.
LoRA: Low-Rank Adaptation of Large Language Models
tatsu-lab/stanford_alpaca
•
•
ICLR 2022
We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
Regularizing and Optimizing LSTM Language Models
salesforce/awd-lstm-lm
•
•
ICLR 2018
Recurrent neural networks (RNNs), such as long short-term memory networks (LSTMs), serve as a fundamental building block for many sequence learning tasks, including machine translation, language modeling, and question answering.
Deep contextualized word representations
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e. g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i. e., to model polysemy).
End-To-End Memory Networks
facebook/MemNN
•
 •
NeurIPS 2015
•
NeurIPS 2015
For the former our approach is competitive with Memory Networks, but with less supervision.
